I try to read as much as I can when I get a chance. The 45 minute bus ride that takes me home gives me ample time to get a few pages in, and the activity also keeps me away from unwanted conversations with other passengers. However, a few weeks ago I did get into a very interesting conversation with a fellow passenger who also happens to be the librarian at the Central library. As the conversation drifted to the favorite books and authors section, I realized my reading map was all over the place and I was unable to recollect several things about the books I had ever read. I decided to us this opportunity to catalog the books I had read, and throw in some data analytics to try squeeze some information out.
I have used Goodreads to catalog the books I have read in the recent years. I had also retroactively added many books from my college days into the website. I did not bother to add many of the Fairy tales, Famous Five, Secret Seven or the Hardy Boys books. Sure, those books set me up to become an active reader later in my life but I think it is safe to say that I have outgrown those books. I was able to export the Goodreads shelves to a spreadsheet and I had in my hands a definitive list of books I had read, and wanted to read. The plan was to throw this dataset into an analytic platform such as spotfire, or powerBI and study my reading habits.
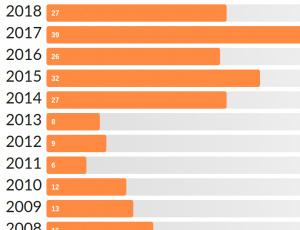
The First thing that bothered me about the list was the number of books I had read. Currently as of September 9th 2018 I have apparently read 275 books. (Excluding the books earlier seems stupid, now!) According to a study done by lithub the average reader reads 12 books a year. I averaged 8. I have always been shocked at how extraordinarily ordinary I have been my entire life. While the Goodreads website has a couple of useful tools like Reading Stats and Most Read authors I was disappointed to see that the exported list did not associate a book to a genre. I have started to read more in the recent years than in the past, so hopefully I will catch up to the average number.
I later found out the as Goodreads allows a book to be cataloged under multiple genres, it does not support the genre field in the exported list. Another challenge that i faced was to figure out how to keep my local copy updated with the books i update on the website. As i was pondering over the problem, a colleague showed me a pet project that he had done with Excel. I was actually surprised at the data processing and analysis ability Microsoft has added into excel in the recent years. No wonder, it still remains as the favorite go to tool for several engineers.
So i set up an excel spreadsheet that was connected to the “Exported” file from Goodreads. This allowed me to refresh my core dataset every time i had a new file from goodreads at the click of a button. I set up a secondary data set that mapped each book title from the exported dataset to a Genre. This i had to do manually, it was tedious but in about an hour i had mapped all the titles i had to a genre. The final step was to setup a “join” in excel that combined the titles along with the genres. Doing that gave me a final dataset of what i wanted. The books i had read, along with metadata like dates read, author names, genre and publication year. I had struck gold in terms of data analysis. I threw this information into the Pivot table of feature and this is what i found.

Fiction was by far what i read the most. I also apparently have a strong preference for Thrillers, Fantasy Fiction and also have a preference for books on philosophy, religion and biographies. Who knew? It seems that i have picked up on the range in the last few years. Hopefully, i will hear about more fantastic books and so will you in the near future. In the mean time do visit Literary Hub and Maria Popova’s blog. You might well be surprised. Happy Reading.
Leave a Reply